Linear Algebra
Contents
![]()
6. Linear Algebra#
Linear Algebra is a discipline where vector spaces and linear mapping between them are studied. In physics and astronomy, several phenomena can be readily written in terms of linear variables, what makes Computational Linear Algebra a very important topic to be covered throughout this course. We shall cover linear systems of equations, techniques for calculating inverses and determinants and factorization methods.
An interesting fact of Computational Linear Algebra is that it does not comprises numerical approaches as most of the methods are exact. The usage of a computer is then necessary because of the large number of calculations rather than the non-soluble nature of the problems. Numerical errors come then from round-off approximations.
See: http://pages.cs.wisc.edu/~amos/412/lecture-notes/lecture14.pdf
Contents
from IPython.display import HTML, Markdown, YouTubeVideo,Latex
%pylab inline
import numpy as np
import matplotlib.pyplot as plt
## JSAnimation import available at https://github.com/jakevdp/JSAnimation
#from JSAnimation import IPython_display
from matplotlib import animation
#Interpolation add-on
import scipy.interpolate as interp
xrange=range
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
https://stackoverflow.com/a/50748163
try:
from google.colab.output._publish import javascript
from IPython.display import Math as math
from IPython.display import Latex as latex
url = "https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.3/latest.js?config=default"
def Math(*args,**kwargs):
javascript(url=url)
return math(*args,**kwargs)
def Latex(*args,**kwargs):
#print(args[0].replace('$',''))
javascript(url=url)
return math(args[0],**kwargs)
except:
from IPython.display import Math, Latex
6.1. Matrices in Python#
One of the most useful advantages of high level languages like Python, is the manipulation of complex objects like matrices and vectors. For this part we are going to use advanced capabilities for handling matrices, provided by the library NumPy.
NumPy, besides the extreme useful NumPy array objects, which are like tensors of any rank, also provides the Matrix objects that are overloaded with proper matrix operations.
6.1.1. Numpy arrays#
A matrix can be represented by an array of two indices
#NumPy Arrays
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
M2 = np.array( a[[3,-2,1],[-1,5,4],[1,-2,3]] )
print( f'M1=\n{M1}, with shape={M1.shape},\n\nM2=\n{M2}' )
M1=
[[ 5 -4 0]
[-4 7 -3]
[ 0 -3 5]], with shape=(3, 3),
M2=
[[ 3 -2 1]
[-1 5 4]
[ 1 -2 3]]
Note tha the previous definitions correspond to integer arrays.
WARNING: Be careful with integer arrays. In the next example, a single float entry convert the full matrix from an integer array to a float array:
M1[0,0]
5
float
np.array([[ 5, -4, 0],
[-4, 7, -3.],
[ 0, -3, 5]])#[0,0]
array([[ 5., -4., 0.],
[-4., 7., -3.],
[ 0., -3., 5.]])
M1/3
array([[ 1.66666667, -1.33333333, 0. ],
[-1.33333333, 2.33333333, -1. ],
[ 0. , -1. , 1.66666667]])
(M1/3).astype(int)
array([[ 1, -1, 0],
[-1, 2, -1],
[ 0, -1, 1]])
6.1.1.1. Special arrays:#
Let \(n\) the range of the matrix
zero matrix
n=3
np.zeros( (n,n) )
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
Ones matrix
np.ones( (n,n) )
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
np.ones( (n,n) )*1j
array([[0.+1.j, 0.+1.j, 0.+1.j],
[0.+1.j, 0.+1.j, 0.+1.j],
[0.+1.j, 0.+1.j, 0.+1.j]])
Identity matrix
np.identity(n)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
np.diag([1,2,4])
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 4]])
Random matrix with entries between 0 and 1
np.random.random()
0.9460452544468382
#np.random.seed(986554575)
np.random.random((n,n))
array([[0.05016015, 0.81396332, 0.17984221],
[0.46070592, 0.46019579, 0.9506249 ],
[0.28245888, 0.83429461, 0.47399034]])
np.random.uniform(0,10,(n,n))
array([[5.16683546, 5.73486742, 4.15495224],
[0.75064986, 0.18470119, 3.9795813 ],
[0.59178719, 6.74641986, 7.40144976]])
Integer Random matrix
np.random.randint(0,10,(n,n)) #0 to 9
array([[9, 1, 9],
[1, 8, 4],
[0, 4, 2]])
np.random.randint(-10,10,(n,n))
array([[ 4, -3, -5],
[ 7, 2, -9],
[-10, 5, -8]])
6.1.1.2. Analytical matrices#
Some times it is necessary to work with analytical Matrices. In such a case we can use the symbolic module Sympy
import sympy
x =sympy.Symbol('x') ## declare analytical varibles
sympy.init_printing() ## Use LaTeX to print sympy obejects
import numpy as np
#NumPy Arrays
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
M2 = np.array( [[3,-2,1],[-1,5,4],[1,-2,3]] )
sympy.Matrix(M2)
In the following we will focus only in numerical matrices as numpy arrays, but also use sympy to print the matrices in a more readable way
6.1.1.3. Matrix operations (numpy)#
Both as functions or array’s methods
Transpose
\(M_2^{\rm T}=\)
from IPython import display
#Latex(r'M_2^{\rm T}=')
sympy.Matrix( M2.transpose())
Matrix addition
sympy.Matrix(M1)
sympy.Matrix(M2)
sympy.Matrix( M1+M2 )
Complex arrays are allowed
Mc=M1+M2*1j
sympy.Matrix( M1+M2*1j )
with the corresponding complex matrix operations
display ( sympy.Matrix( Mc.conjugate() ) )
display ( sympy.Matrix( Mc.conjugate().transpose() ) ) ## hermitian-conjugate
Matrix multiplication

dot(a, b, out=None)
Dot product of two arrays. Specifically,
If both
aandbare 1-D arrays, it is inner product of vectors (without complex conjugation).If both
aandbare 2-D arrays, it is matrix multiplication, but using :func:matmulora @ bis preferred.If either
aorbis 0-D (scalar), it is equivalent to :func:multiplyand usingnumpy.multiply(a, b)ora * bis preferred.…
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
M2 = np.array( [[3,-2,1],
[-1,5,4],
[1,-2,3]] )
#Multiplication
sympy.Matrix( np.dot( M1, M2 ) )
sympy.Matrix( M1.dot(M2) )
Recommended way
sympy.Matrix(M1@M2)
np.array( [1,2])@np.array( [[1],[2]])
array([5])
#Multiplication is not commutative
sympy.Matrix ( M2@M1 )
Complex matrices
σ_2=np.array(
[[0,-1j],
[1j,0]])
sympy.Matrix(σ_2)
Trace
np.trace(σ_2)
0j
Determinant
np.linalg.det(σ_2)
(-1+0j)
Raise a square matrix to the (integer) power n.
sympy.Matrix ( np.linalg.matrix_power(σ_2,2) )
(σ_2@σ_2).astype(float)
/tmp/ipykernel_12325/501469815.py:1: ComplexWarning: Casting complex values to real discards the imaginary part
(σ_2@σ_2).astype(float)
array([[1., 0.],
[0., 1.]])
odd power
sympy.Matrix ( np.linalg.matrix_power(σ_2,7) )
even power
sympy.Matrix ( np.linalg.matrix_power(σ_2,14) )
Inverse of a matrix
sympy.Matrix( np.linalg.inv(M2) )
sympy.Matrix ( ( M2@np.linalg.inv(M2) ).round(15) )
( M2@np.linalg.inv(M2) ).round(15).astype(int)
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]])
sympy.Matrix ( ( M2@np.linalg.inv(M2) ).round(15).astype(int) )
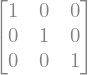
6.1.1.4. Element by element operations#
print(M1)
M2
[[ 5 -4 0]
[-4 7 -3]
[ 0 -3 5]]
array([[ 3, -2, 1],
[-1, 5, 4],
[ 1, -2, 3]])
M1*M2
array([[ 15, 8, 0],
[ 4, 35, -12],
[ 0, 6, 15]])
#Division
print( M1/M2 )
[[ 1.66666667 2. 0. ]
[ 4. 1.4 -0.75 ]
[ 0. 1.5 1.66666667]]
sympy.Matrix( M1@np.linalg.inv(M2).round(3) )
6.1.1.5. Submatrix from matrix:#
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
Elements of the matrix
M1[1,2]
-3
6.1.1.6. Extract rows#
M1[1,:]
array([-4, 7, -3])
or
M1[1]
array([-4, 7, -3])
In general:
M1[list of rows to extract]
M1[[1]]
array([[-4, 7, -3]])
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
M1[[0,2]]
array([[ 5, -4, 0],
[ 0, -3, 5]])
6.1.1.7. Extract columns#
M1[:,1]
array([-4, 7, -3])
and convert back into a column
np.c_[M1[:,1]]
array([[-4],
[ 7],
[-3]])
6.1.1.8. Reordering#
M1 = np.array( [[ 5 ,-4, 0],
[-4 , 7,-3],
[ 0 ,-3, 5]] )
Reverse row order to 2,1,0
M1[[2,1,0]]
array([[ 0, -3, 5],
[-4, 7, -3],
[ 5, -4, 0]])
or
np.r_[[M1[2]],[M1[1]],[M1[0]]]
array([[ 0, -3, 5],
[-4, 7, -3],
[ 5, -4, 0]])
Reverse column order to 2,1,0
np.c_[ M1[:,2],M1[:,1],M1[:,0] ]
array([[ 0, -4, 5],
[-3, 7, -4],
[ 5, -3, 0]])
6.1.1.9. It is possible to reasign a full set of rows to a matrix#
M1 = np.array( [[ 5,-4, 0],
[-4, 7,-3],
[ 0,-3, 5]] )
M1[[0,2]]=[[0 ,0,0.3],
[0.3,0,0 ]]
M1
array([[ 0, 0, 0],
[-4, 7, -3],
[ 0, 0, 0]])
Note that because M1 has only integer numbers, it is assumed to be an integer matrix. In order to allow float assignments, it is first necessary to convert to a float matrix:
M1=M1.astype(float)
M1[[0,2]]=[[0 ,0,0.3],
[0.3,0,0 ]]
M1
array([[ 0. , 0. , 0.3],
[-4. , 7. , -3. ],
[ 0.3, 0. , 0. ]])
WARNING
In some cases a reasignment of a list or array points to the same space in memory. To really copy an array to other variable it is always recommended to use the .copy() method.
A=np.array([1,2])
A
array([1, 2])
Reassign memory space
C=A
C
array([1, 2])
A change is reflected in both variables
C[0]=5
print(f'A={A} → C={C}')
A=[5 2] → C=[5 2]
A[1]=8
print(f'A={A} → C={C}')
A=[5 8] → C=[5 8]
To keep the first memory space
B=A.copy() ## two different memory spaces
B[0]=4
print('A =',A)
print('B =',B)
A = [5 2]
B = [4 2]
6.1.1.10. Matrix object#
numpy also has a Matrix object with simplified operations. However it is recommended to use the general array object even for specific matrix operations. This helps to avoid incompatibilities with usual array operations. For example, as shown below the multiplication symbol, *, behaves different for arrays that for matrices, and could induce to errors.
#NumPy Matrix
M1 = np.matrix( [[5,-4,0],[-4,7,-3],[0,-3,5]] )
M2 = np.matrix( [[3,-2,1],[-1,5,4],[1,-2,3]] )
print (M1, "\n")
print (M2)
[[ 5 -4 0]
[-4 7 -3]
[ 0 -3 5]]
[[ 3 -2 1]
[-1 5 4]
[ 1 -2 3]]
#Addition
sympy.Matrix( M1+M2 )
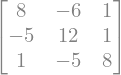
#Multiplication
sympy.Matrix( M1*M2 )
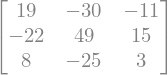
6.1.2. Basic operations with matrices#
In order to simplify the following methods, we introduce here 3 basic operations over linear systems:
The \(i\)-th row \(E_i\) can be multiplied by a non-zero constant \(\lambda\), and then a new row used in place of \(E_i\), i.e. \((E_i)\rightarrow (\lambda E_i)\). We denote this operation as \(\operatorname{Lamb}(E_i,\lambda)\).
The \(j\)-th row \(E_j\) can be multiplied by a non-zero constant \(\lambda\) and added to some row \(E_i\). The resulting value take the place of \(E_i\), i.e. \((E_i) \rightarrow (E_i + \lambda E_j)\). We denote this operation as \(\operatorname{Comb}(E_i,E_j,\lambda)\).
Finally, we define a swapping of two rows as \((E_i)\leftrightarrow (E_j)\), denoted as \(\operatorname{Swap}(E_i,E_j)\)
6.1.2.1. Extract rows from an array#
6.1.3. Activity #
Write three routines that perform, given a matrix \(A\), the previous operations over matrices:
row_lamb(i, λ, A):iis the row to be changed,λthe multiplicative factor andAthe matrix. This function should return the new matrix with the performed operation \((E_i)\rightarrow (\lambda E_i)\).row_comb(i, j, λ, A):iis the row to be changed,jthe row to be added,λthe multiplicative factor andAthe matrix. This function should return the new matrix with the performed operation \((E_i) \rightarrow (E_i + \lambda E_j)\).row_swap(i, j, A):iandjare the rows to be swapped. This function should return the new matrix with the performed operation \((E_i)\leftrightarrow (E_j)\).
import numbers
isinstance(np.array([2])[0],numbers.Integral)
True
M1=M1.astype(float)
M1
array([[ 2., -4., 0.],
[-4., 7., -3.],
[ 0., -3., 5.]])
M1.dtype==np.dtype('int64')
False
def row_sawp(i,j,A):
'''
i and j are the rows to be swapped
'''
B=A.copy()
B[[i,j]]=B[[j,i]]
return B
def row_comb(i,j,λ,A):
'''
`i` is the row to be changed,
`j` the row to be added
`λ` the multiplicative factor
`A` the matrix.
operation
---------
E_i→ E_i+λ*E_j
'''
B=A.copy()
if B.dtype==np.dtype('int64'):
B=B.astype(float)
B[i]=B[i]+λ*B[j]
return B
def row_lamb(i,λ,A):
'''
`i` is the row to be changed,
`λ` the multiplicative factor
`A` the matrix.
operation
---------
λ → λ*E_i
'''
B=A.copy()
if B.dtype==np.dtype('int64'):
B=B.astype(float)
B[i]=λ*B[i]
return B
Check with
import numpy as np
import sympy
M1=np.array( [[5,-4,0],[-4,7,-3],[0,-3,5]] )
M1
array([[ 5, -4, 0],
[-4, 7, -3],
[ 0, -3, 5]])
row_lamb(1,3.4,M1)
array([[ 5. , -4. , 0. ],
[-13.6, 23.8, -10.2],
[ 0. , -3. , 5. ]])
row_comb(0,1,5/4,M1)
array([[ 0. , 4.75, -3.75],
[-4. , 7. , -3. ],
[ 0. , -3. , 5. ]])
row_sawp(0,1,M1)
array([[-4, 7, -3],
[ 5, -4, 0],
[ 0, -3, 5]])
6.2. Gaussian Elimination#
6.2.1. Example 1#
Using Kirchhoff’s circuit laws, it is possible to solve the next system:
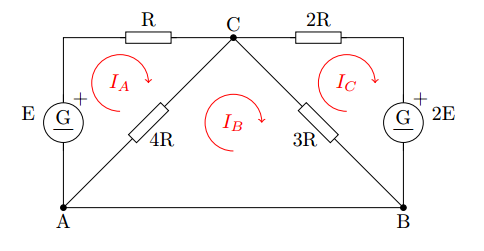
obtaining the next equations:
or
Defining the variables \(x_1 = R I_A/E\), \(x_2 = R I_B/E\) and \(x_3 = R I_C/E\) we have
A first method to solve linear systems of equations is the Gaussian elimination. This procedure consists of a set of recursive steps performed in order to diagonalise the matrix of the problem. A suitable way to introduce this method is applying it to some basic problem. To do so, let’s take the result of the Example 1:
Constructing the associated augmented matrix, we obtain
6.2.1.1. Activity #
Use numpy functions to build the augmented matrix M1
M1 = np.array( [[5,-4,0],[-4,7,-3],[0,-3,5]] )
sympy.Matrix(M1)
np.array( [[1],[0],[-2]] )
array([[ 1],
[ 0],
[-2]])
M1_aug=np.c_[ M1, [[1],[0],[-2]] ]
sympy.Matrix(M1_aug)
or
M1_aug=np.hstack( (M1,[[1],[0],[-2]]))
sympy.Matrix(M1_aug)
At this point, we can eliminate the coefficients of the variable \(x_1\) in the second and third equations. For this, we apply the operations \(\operatorname{Comb}(E_2,E_1,4/5)\).
\(E_2\) → [-4,7,-3⋮0]+[4,-16/5,0⋮4/5]=[0,19/5,-3⋮4/5]
The coefficient in the third equation is already null. We then obtain:
M1_LU=row_comb(1,0,4/5,M1_aug)
M1_LU
array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8, -3. , 0.8],
[ 0. , -3. , 5. , -2. ]])
Now, we proceed to eliminate the coefficient of \(x_2\) in the third equation. For this, we apply again \(\operatorname{Comb}(E_3,E_2,3\cdot 5/19)\)
\(E_3\) → [0,-3,5⋮-2]+[0,(3*5/19)*(19/5),-(3*5/19)*3⋮(3*5/19)*4/5]→[0,0,50/19⋮-26/19]
M1_LU=row_comb(2,1,3*5/19,M1_LU)
M1_LU
array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8 , -3. , 0.8 ],
[ 0. , 0. , 2.63157895, -1.36842105]])
M1_LU
array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8 , -3. , 0.8 ],
[ 0. , 0. , 2.63157895, -1.36842105]])
The final step is to solve for \(x_3\) in the last equation, doing the operation \(\operatorname{Lamb}(E_3,19/50)\), yielding:
From this, it is direct to conclude that \(x_3 = -26/50=-0.52\), for \(x_2\) and \(x_1\) it is only necessary to replace the found value of \(x_3\).
row_lamb(2,19/50,M1_LU)
array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8 , -3. , 0.8 ],
[ 0. , 0. , 1. , -0.52]])
The full implementation in numpy is with np.linalg.solve
np.linalg.solve?
np.linalg.solve(M1,[1,0,-2])
array([ 0.04, -0.2 , -0.52])
np.linalg.solve(M1,[[1],[0],[-2]])
array([[ 0.04],
[-0.2 ],
[-0.52]])
6.3. Linear Systems of Equations#
A linear system is a set of equations of \(n\) variables that can be written in a general form:
where \(n\) is, again, the number of variables, and \(m\) the number of equations.
A linear system has solution if and only if \(m\geq n\). This leads us to the main objetive of a linear system, find the set \(\{x_i\}_{i=0}^n\) that fulfills all the equations.
Although there is an intuitive way to solve this type of systems, by just adding and subtracting equations until reaching the desire result, the large number of variables of some systems found in physics and astronomy makes necessary to develop iterative and general approaches. Next, we shall introduce matrix and vector notation and some basic operations that will be the basis of the methods to be developed in this section.
Quadratic eqution…
6.3.1. Matrices and vectors#
A \(m\times n\) matrix can be defined as a set of numbers arranged in columns and rows such as:
In the same way, it is possible to define a \(n\)-dimensional column vector as
and a column vector of constant coefficients
The system of equations
can be then written in a more convenient way as
We can also introducing the \(n\times (n+1)\) augmented matrix as
6.3.1.1. Implementation in Scipy#
import scipy.linalg as linalg
linalg.lu?
M1_aug
array([[ 5, -4, 0, 1],
[-4, 7, -3, 0],
[ 0, -3, 5, -2]])
P,L,U=linalg.lu(M1_aug)
U
array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8 , -3. , 0.8 ],
[ 0. , 0. , 2.63157895, -1.36842105]])
\(x_3\) is now
x3=U[2,3]/U[2,2]
'x3=-26/50={:.2f}'.format(x3)
'x3=-26/50=-0.52'
x2=(U[1,3]-U[1,2]*x3)/U[1,1]
round(x2,2)
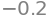
x1=( U[0,3]-U[0,1]*x2-U[0,2]*x3 )/U[0,0]
round(x1,2)
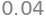
6.3.2. General Gaussian elimination#
Now, we shall describe the general procedure for Gaussian elimination:
Give an augmented matrix \(\hat{A}=[A:\textbf{b}]\).
Find the first non-zero coefficient \(a_{i1}\) associated to \(x_1\). This element is called pivot.
Apply the operation \(\operatorname{Swap}(E_1,E_i)\). This guarantee the first row has a non-zero coefficient \(a_{11}\).
Apply the operation \(\operatorname{Comb}(E_j,E_1,-a_{j1}/a_{11})\). This eliminates the coefficients associated to \(x_1\) in all the rows but in the first one.
Repeat steps 2. to 4. but for the coefficients of \(x_2\) and then \(x_3\) and so up to \(x_n\). When iterating the coefficients of \(x_{k}\), do not take into account the first \(k\)-th rows as they are already sorted.
Once you obtain a diagonal form of the matrix, apply the operation \(\operatorname{Lamb}(E_n,1/a_{nn})\). This will make the coefficient of \(x_n\) in the last equation equal to 1.
The final result should be an augmented matrix of the form: $\(\left[ \matrix{ a_{11} & a_{12} & \cdots & a_{1(n-1)} & a_{1n} & \vdots & \hat b_1 \\ 0 & a_{22} & \cdots & a_{2(n-1)} & a_{2n} & \vdots & \hat b_2 \\ \vdots & \vdots & & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & \cdots & a_{(n-1)(n-1)} & a_{(n-1)n} & \vdots & \hat b_{n-1} \\ 0 & 0 & \cdots & 0 & 1 & \vdots & \hat b_n }\right]\)$
The solution to the problem is then obtained through backward substitutions, i.e. $\(x_n = \hat b_n\)\( \)\( x_{n-1} = \frac{\hat b_{n-1} - a_{(n-1)n}x_n}{a_{(n-1)(n-1)}}\)\( \)\(\vdots\)\( \)\(x_i = \frac{\hat b_i - \sum_{j=i+1}^n a_{ij}x_j}{a_{ii}}\ \ \ \ \mbox{for}\ \ \ i=n-1, n-2, \cdots, 1\)$
See custom implementation of general Gaussian elimination
#Gaussian Elimination
import scipy
def Gaussian_Elimination( A0 ):
#Making local copy of matrix
P,L,A=scipy.linalg.lu(A0)
n = len(A)
#Finding solution
x = np.zeros( n )
x[n-1] = A[n-1,n]
for i in range( n-1, -1, -1 ):
x[i] = ( A[i,n] - sum(A[i,i+1:n]*x[i+1:n]) )/A[i,i]
#Upper diagonal matrix and solutions x
return A, x
np.random.seed(3)
M = np.random.random( (4,5) )
M
array([[0.5507979 , 0.70814782, 0.29090474, 0.51082761, 0.89294695],
[0.89629309, 0.12558531, 0.20724288, 0.0514672 , 0.44080984],
[0.02987621, 0.45683322, 0.64914405, 0.27848728, 0.6762549 ],
[0.59086282, 0.02398188, 0.55885409, 0.25925245, 0.4151012 ]])
U,x=Gaussian_Elimination(M)
Upper triangular
U
array([[ 0.89629309, 0.12558531, 0.20724288, 0.0514672 , 0.44080984],
[ 0. , 0.63097203, 0.16354802, 0.47919953, 0.62205662],
[ 0. , 0. , 0.52490983, -0.06699671, 0.21531002],
[ 0. , 0. , 0. , 0.32582312, 0.00303691]])
solutions
x
array([0.27395594, 0.8721633 , 0.41137442, 0.00932074])
M1_aug
array([[ 5, -4, 0, 1],
[-4, 7, -3, 0],
[ 0, -3, 5, -2]])
Gaussian_Elimination(M1_aug)
(array([[ 5. , -4. , 0. , 1. ],
[ 0. , 3.8 , -3. , 0.8 ],
[ 0. , 0. , 2.63157895, -1.36842105]]),
array([ 0.04, -0.2 , -0.52]))
6.3.3. Pivoting Strategies#
The previous method of Gaussian Elimination for finding solutions of linear systems is mathematically exact, however round-off errors that appear in computational arithmetics can represent a real problem when high accuracy is required.
In order to illustrate this, consider the next situation:
Using four-digit arithmetic we obtain:
1. Constructing the augmented matrix:
2. Applying the reduction with the first pivot, we obtain:
where:
In this step, we have taken the first four digits. This leads us to:
The exact system is instead
Using the solution \(x_2 \approx 1.001\), we obtain
The exact solution is however:
The source of such a large error is that the factor \(59.14/0.00300 \approx 20000\). This quantity is propagated through the combination steps of the Gaussian Elimination, yielding a complete wrong result.
6.3.4. Computing time#
As mentioned before, Algebra Linear methods do not invole numerical approximations excepting round-off errors. This implies the computing time depends on the number of involved operations (multiplications, divisions, additions and subtractions). It is possible to demonstrate that the numbers of required divisions/multiplications is given by:
and the required additions/subtractions:
These numbers are calculated separately as the computing time per operation for divisions and multiplications are similar and much larger than computing times for additions and subtractions. According to this, the overall computing time, for large \(n\), scales as \(n^3\)/3.
6.3.5. Example 2#
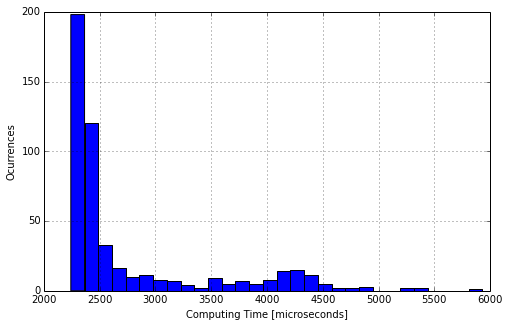
Using the library datetime of python, evaluate the computing time required for Gaussian_Elimination to find the solution of a system of \(n=20\) equations and \(20\) unknowns. For this purpose you can generate random systems. For a more robust result, repeat \(500\) times, give a mean value and plot an histrogram of the computing times.
#Importing datatime
from datetime import datetime
#Number of repeats
Nrep = 500
#Size of matrix
n = 20
def Gaussian_Time( n, Nrep ):
#Arrays of times
Times = []
#Cicle for number of repeats
for i in xrange(Nrep):
#Generating random matrix
M = np.matrix( np.random.random( (n,n+1) ) )
#Starting time counter
tstart = datetime.now()
#Invoking Gaussian Elimination routine
Gaussian_Elimination(M)
#Killing time counter
tend = datetime.now()
#Saving computing time
Times.append( (tend-tstart).microseconds )
#Numpy Array
Times = np.array(Times)
print "The mean computing time for a %dx%d matrix is: %lf microseconds"%(n,n,Times.mean())
#Histrogram
plt.figure( figsize=(8,5) )
histo = plt.hist( Times, bins = 30 )
plt.xlabel( "Computing Time [microseconds]" )
plt.ylabel( "Ocurrences" )
plt.grid()
return Times.mean()
Gaussian_Time( n, Nrep )
The mean computing time for a 20x20 matrix is: 2762.628000 microseconds
2762.6280000000002
6.3.6. Activity #
Using the previous code, estimate the computing time for random matrices of size \(n=5,10,50,100,500,1000\). For each size, compute \(500\) times in order to reduce spurious errors. Plot the results in a figure of \(n\) vs computing time. Is it verified the some of scaling laws (Multiplication/Division or Addition/Sustraction). Note that for large values of \(n\), both scaling laws converge to the same.
6.3.7. Partial pivoting#
A suitable method to reduce round-off errors is to choose a pivot more conveniently. As we saw before, a small pivot generally implies larger propagated errors as they appear usually as dividends. The partial pivoting method consists then of a choosing of the largest absolute coefficient associated to \(x_i\) instead of the first non-null one, i.e.
This way, propagated multiplication errors would be minimized.
6.3.8. Activity #
Create a new routine Gaussian_Elimination_Pivoting from Gaussian_Elimination in order to include the partial pivoting method. Compare both routines with some random matrix and with the exact solution.
6.4. Matrix Inversion#
Asumming a nonsingular matrix \(A\), if a matrix \(A^{-1}\) exists, with \(AA^{-1} = I\) and \(A^{-1}A = I\), where \(I\) is the identity matrix, then \(A^{-1}\) is called the inverse matrix of \(A\). If such a matrix does not exist, \(A\) is said to be a singular matrix.
A corollary of this definition is that \(A\) is also the inverse matrix of \(A^{-1}\).
Once defined the Gaussian Elimination method, it is possible to extend it in order to find the inverse of any nonsingular matrix. Let’s consider the next equation:
This can be rewritten as a set of \(n\) systems of equations, i.e.
These systems can be solved individually by using Gaussian Elimination, however we can mix all the problems, obtaining the augmented matrix:
Now, applying Gaussian Elimination we can obtain a upper diagonal form for the first matrix. Completing the steps using forwards elimination we can convert the first matrix into the identity matrix, obtaining
Where the second matrix is then the inverse \(B=A^{-1}\).
6.4.1. Activity #
Using the previous routine Gaussian_Elimination_Pivoting, create a new routine Inverse that calculates the inverse of any given squared matrix.
6.5. Determinant of a Matrix#
The determinant of a matrix is a scalar quantity calculated for square matrix. This provides important information about the matrix of coefficients of a system of linear of equations. For example, any system of \(n\) equations and \(n\) unknowns has an unique solution if the associated determinant is nonzero. This also implies the determinant allows to evaluate whether a matrix is singular or nonsingular.
6.5.1. Calculating determinants#
Next, we shall define some properties of determinants that will allow us to calculate determinants by using a recursive code:
1. If \(A = [a]\) is a \(1\times 1\) matrix, its determinant is then \(\det A = a\).
2. If \(A\) is a \(n\times n\) matrix, the minor matrix \(M_{ij}\) is the determinant of the \((n-1)\times(n-1)\) matrix obtained by deleting the \(i\)th row and the \(j\)th column.
3. The cofactor \(A_{ij}\) associated with \(M_{ij}\) is defined by \(A_{ij} = (-1)^{i+j}M_{ij}\).
4. The determinant of a \(n\times n\) matrix \(A\) is given by:
or
This is, it is possible to use both, a row or a column for calculating the determinant.
6.5.2. Computing time of determinants#
Using the previous recurrence, we can calculate the computing time of the previous algorithm. First, let’s consider the number of required operations for a \(2\times 2\) matrix: let \(A\) be a \(2\times 2\) matrix given by:
The determinant is then given by:
the number of required multiplications was \(2\) and subtractions is \(1\).
Now, using the previous formula for the determinant
For a \(3\times 3\) matrix, it is necessary to calculate \(3\) times \(2\times 2\) determinants. Besides, it is necessary to multiply the cofactor \(A_{ij}\) with the coefficient \(a_{ij}\), that leads us with \(t_{n=3}=3\times 2 + 3\) multiplications. Additions are not important as their computing time is far less than multiplications.
For a \(4\times 4\) matrix, we need four deteminants of \(3\times 3\) submatrices, leading \(t_{n=4} = 4\times( 3\times 2 + 3 ) + 4 = 4! + \frac{4!}{2!} + \frac{4!}{3!}\). In general, for a \(n\times n\) matrix, we have then:
If \(n\) is large enough, we can approximate \(t_{n}\approx n!\).
In computers, this is a prohibitive computing time so other schemes have to be proposed.
6.5.3. Activity #
Evaluate the computing time of the Determinant routine for matrix sizes of \(n=1,2,3,\cdots,10\) and doing several repeats. Plot your result (\(n\) vs \(t_n\)). What can you conclude about the behaviour of the computing time?
6.5.4. Properties of determinants#
Determinants have a set of properties that can reduce considerably computing times. Suppose \(A\) is a \(n\times n\) matrix:
1. If any row or column of \(A\) has only zero entries, then \(\det A = 0\).
2. If two rows or columns of \(A\) are the same, then \(\det A = 0\).
3. If \(\hat A\) is obtained from \(A\) by using a swap operation \((E_i)\leftrightarrow (E_j)\), then \(\det \hat A=-\det A\).
4. If \(\hat A\) is obtained from \(A\) by using a escalation operation \((\lambda E_i)\leftrightarrow (E_i)\), then \(\det \hat A=\lambda \det A\).
5. If \(\hat A\) is obtained from \(A\) by using a combination operation \((E_i+\lambda E_j) \leftrightarrow (E_i)\), then \(\det \hat A=\det A\).
6. If \(B\) is also a \(n\times n\) matrix, then \(\det(AB)=(\det A)(\det B).\)
7. \(\det A^t=\det A.\)
8. \(\det A^{-1}=(\det A)^{-1}\)
9. Finally and most importantly: if \(A\) is an upper, lower or diagonal matrix, then:
As we analysed before, Gaussian Elimination takes a computing time scaling like \(n^3\) for large matrix sizes. According to the previous properties, the determinant of a upper diagonal matrix just takes \(n-1\) multiplications, far less than a nondiagonal matrix. Combining these properties, we can track back and relate the determinant of the resulting upper diagonal matrix and the original one. Leading us to a computing time scaling like \(n^3\), much better than the original \(n!\).
6.5.5. Activity #
Using the Gaussian_Elimination routine and tracking back the performed operations, construct a new routine called Gaussian_Determinant. Make the same analysis of the computing time as the previous activity. Compare both results.
6.5.6. Existence of inverse#
A matrix \(A\) has an inverse if \(\det{A}\ne 0\). See for example here
If the matrix \(A\) has an inverse, then
Example From the previous example
np.random.seed(3)
M = np.random.random( (4,5) )
M
array([[0.5507979 , 0.70814782, 0.29090474, 0.51082761, 0.89294695],
[0.89629309, 0.12558531, 0.20724288, 0.0514672 , 0.44080984],
[0.02987621, 0.45683322, 0.64914405, 0.27848728, 0.6762549 ],
[0.59086282, 0.02398188, 0.55885409, 0.25925245, 0.4151012 ]])
M[:,0]
array([0.5507979 , 0.89629309, 0.02987621, 0.59086282])
np.c_[M[:,0]]
array([[0.5507979 ],
[0.89629309],
[0.02987621],
[0.59086282]])
A=np.c_[ tuple( [ np.c_[M[:,i]] for i in range(4) ] ) ]
A
array([[0.5507979 , 0.70814782, 0.29090474, 0.51082761],
[0.89629309, 0.12558531, 0.20724288, 0.0514672 ],
[0.02987621, 0.45683322, 0.64914405, 0.27848728],
[0.59086282, 0.02398188, 0.55885409, 0.25925245]])
b=np.c_[ M[:,4] ]
b
array([[0.89294695],
[0.44080984],
[0.6762549 ],
[0.4151012 ]])
such that
Check that \(A\) has an inverse and calculate \(\boldsymbol{x}\)
np.linalg.det(A)

\(\boldsymbol{x}=\)
sympy.Matrix( np.dot( np.linalg.inv(A) , b).round(4) )
6.5.6.1. Numpy implementation#
np.linalg.solve(A,b)
array([[0.27395594],
[0.8721633 ],
[0.41137442],
[0.00932074]])
np.linalg.solve(A,M[:,4])
array([0.27395594, 0.8721633 , 0.41137442, 0.00932074])
6.6. Matrix diagonalization#
6.7. LU Factorization#
As we saw before, the Gaussian Elimination algorithm takes a computing time scaling as \(\mathcal{O}(n^3/3)\) in order to solve a system of \(n\) equations and \(n\) unknowns. Let’s assume a system of equations \(\mathbf{A}\mathbf{x} = \mathbf{b}\) where \(\mathbf{b}\) is already in upper diagonal form.
The Gauss-Jordan algorithm can reduce even more this problem in order to solve it directly, yielding:
From the upper diagonal form to the completely reduced one, it is necessary to perform \(n+(n-1)+(n-2)+\cdots\propto n(n-1)\) backwards substitutions. The computing time for solving a upper diagonal system is then \(\mathcal{O}(n^2)\).
Now, let \(\mathbf{A}\mathbf{x} = \mathbf{b}\) be a general system of equations of \(n\) dimensions. Let’s assume \(\mathbf{A}\) can be written as a multiplication of two matrices, one lower diagonal \(\mathbf{L}\) and other upper diagonal \(\mathbf{U}\), such that \(\mathbf{A}=\mathbf{L}\mathbf{U}\). Defining a vector \(\mathbf{y} = \mathbf{U}\mathbf{x}\), it is obtained for the original system
For solving this system we can then:
1. Solve the equivalent system \(\mathbf{L}\mathbf{y} = \mathbf{b}\), what takes a computing time of \(\mathcal{O}(n^2)\).
2. Once we know \(\mathbf{y}\), we can solve the system \(\mathbf{U}\mathbf{x} = \mathbf{y}\), with a computing time of \(\mathcal{O}(n^2)\).
The global computing time is then \(\mathcal{O}(2n^2)\)
6.7.1. Activity #
In order to compare the computing time that Gaussian Elimination takes and the previous time for the LU factorization, make a plot of both computing times. What can you conclude when \(n\) becomes large enough?
6.7.2. Derivation of LU factorization#
Although the LU factorization seems to be a far better method for solving linear systems as compared with say Gaussian Elimination, we was assuming we already knew the matrices \(\mathbf{L}\) and \(\mathbf{U}\). Now we are going to see the algorithm for perfoming this reduction takes a computing time of \(\mathcal{O}(n^3/3)\).
You may wonder then, what advantage implies the use of this factorization? Well, matrices \(\mathbf{L}\) and \(\mathbf{U}\) do not depend on the specific system to be solved, i.e. there is not dependence on the \(\mathbf{b}\) vector, so once we have both matrices, we can use them to solve any system we want, just taking a \(\mathcal{O}(2n^2)\) computing time.
First, let’s assume a matrix \(\mathbf{A}\) with all its pivots are nonzero, so there is not need to swap rows. Now, when we want to eliminate all the coefficients associated to \(x_1\), we perform the next operations:
henceforth, \(a^{(1)}_{ij}\) denotes the components of the original matrix \(\mathbf{A}=\mathbf{A}^{(1)}\), \(a^{(2)}_{ij}\) the components of the matrix after eliminating the coefficients of \(x_1\), and generally, \(a^{(k)}_{ij}\) the components of the matrix after eliminating the coefficients of \(x_{k-1}\).
The previous operation over the matrix \(\mathbf{A}\) can be also reproduced defining the matrix \(\mathbf{M}^{(1)}\)
This is called the first Gaussian transformation matrix. From this, we have
where \(\mathbf{A}^{(2)}\) is matrix with null coefficients associated to \(x_1\) but the first one.
Repeating the same procedure for the next pivots, we obtain then
where the \(k\)th Gaussian transformation matrix is defined as
and
Note \(\mathbf{A}^{(n)}\) is a upper diagonal matrix given by
so we can define \(\mathbf{U}\equiv \mathbf{A}^{(n)}\).
Now, taking the equation
and defining the inverse of \(\mathbf{M}^{(k)}\) as
we obtain
where the lower diagonal matrix \(\mathbf{L}\) is given by:
$\( \mathbf{L} = \mathbf{L}^{(1)} \cdots \mathbf{L}^{(n-2)}\mathbf{L}^{(n-1)} \)$.
6.7.3. Algorithm for LU factorization#
The algorithm is then given by:
1. Give a square matrix \(\mathbf{A}\) where the pivots are nonzero.
2. Apply the operation \(Comb(E_j,E_1,-a^{(1)}_{j1}/aa^{(1)}_{11})\). This eliminates the coefficients associated to \(x_1\) in all the rows but in the first one.
3. Construct the matrix \(\mathbf{L}^{(1)}\) given by
with \(k=1\).
4. Repeat the steps 2 and 3 for the next column until reaching the last one.
5. Return the matrices \(\mathbf{U} = \mathbf{A}^{(n)}\) and \( \mathbf{L} = \mathbf{L}^{(1)} \cdots \mathbf{L}^{(n-2)}\mathbf{L}^{(n-1)} \).
6.7.4. Activity #
Create a routine called LU_Factorization that, given a matrix \(\mathbf{A}\) and the previous algorithm, calculate the LU factorization of the matrix. Test your routine with a random square matrix, verify that \(\mathbf{A} = \mathbf{L}\mathbf{U}\).
M1
array([[ 5, -4, 0],
[-4, 7, -3],
[ 0, -3, 5]])
import scipy
P,L,U=scipy.linalg.lu(M1)
U
array([[ 5. , -4. , 0. ],
[ 0. , 3.8 , -3. ],
[ 0. , 0. , 2.63157895]])
The same obtained before
scipy.linalg.lu?
6.7.5. Eigenvalues and Eigenvectors activity #
6.7.5.1. Electron interacting with a magnetic field#
An electron is placed to interact with an uniform magnetic field. To give account of the possible allowed levels of the electron in the presence of the magnetic field it is necessary to solve the next equation
where the hamiltonian is equal to \(H = -\mu \cdot B = -\gamma B \cdot S\), with the gyromagnetic ratio \(\gamma\), \(\textbf{B}\) the magnetic field and \(\textbf{S}\) the spin. It can be shown that the hamiltonian expression is transformed in
Then, by solving the problem \(|H - EI|=0\) is found the allowed energy levels, i.e., finding the determinant of the matrix \(H - EI\) allows to get the values \(E_1\) and \(E_2\).
And solving the problem \(\hat{H}\Psi\) - E\(\Psi = 0\) gives the autofunctions \(\Psi\), i.e., the column vector \(\Psi= \{\Psi_1, \Psi_2\}\).
The function scipy.optimize.root can be used to get roots of a given equation. The experimental value of \(\gamma\) for the electron is 2. The order of magnitude of the magnetic field is \(1g\).
Find the allowed energy levels.
Find the autofunctions and normalize them.
Hint: An imaginary number in python can be written as 1j.